Raft是什么
Raft 是一种共识算法,旨在易于理解。它在容错性和性能方面与 Paxos 相当。不同之处在于,Raft 被分解为相对独立的子问题,并且它清晰地解决了实际系统所需的所有主要部分。目前有不少的应用都是采用Raft协议来保证集群节点一致性,比如ectd,consul
共识是什么
共识通常出现在复制状态机的背景下,这是构建容错系统的一种通用方法。每个服务器都有一个状态机和一个日志。状态机是我们想要使其容错的组件,例如散列表。对于客户端来说,他们将与一个可靠的单个状态机进行交互,即使群集中的一小部分服务器发生故障。每个状态机从其日志中接受命令作为输入。在我们的散列表示例中,日志将包括像将 x 设置为 3 的命令。共识算法用于在服务器的日志中达成命令的一致。共识算法必须确保如果任何一个状态机将第 n 个命令设置 x 为 3,那么没有其他状态机将会应用不同的第 n 个命令。因此,每个状态机处理相同的一系列命令,从而产生相同的一系列结果并到达相同的一系列状态。
即共识在分布式系统下通过复制log的机制,相互通信,确保多台机器下的数据一致性
CAP理论
CAP理论是指分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者只能满足其中的两个,无法同时满足三个特性。该理论由加州大学伯克利分校的计算机科学家Eric Brewer于2000年提出。
一致性指的是分布式系统中的所有节点,在同一时刻看到的数据都应该是一致的。可用性则指的是分布式系统应该保证在任何时候都能够对外提供服务,而分区容错性则是指分布式系统在遭遇网络分区的情况下,仍然能够保持数据的一致性和可用性。
CAP理论认为,在一个分布式系统中,由于网络不可靠或节点故障等原因,系统可能会遭受分区的情况。因此,在这种情况下,我们必须要舍弃一些特性,以保证系统的可用性以及一致性。
在实际开发中,选择一致性、可用性、分区容错性中的两个,将会依据项目本身的需求。例如,针对分布式缓存系统,对于短时间内的数据不一致可以容忍,可用性和分区容错性显得尤为重要;而对于金融行业的分布式交易系统,则需要最高级的数据一致性保障。
Raft能做什么
通过Raft可以用来构建容错系统。在一个容错系统中,如果有一些节点出现故障,仍然可以保证系统正常运行。Raft协议可以用来确保分布式系统中的每个节点都拥有相同的状态。
Raft的原理
Raft将一个节点分为三中状态
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后高速Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告知日志可以提交后,提交日志。当Leader出现故障时,主动推荐自己为候选人。
- Candidate:Leader选举过程中的临时角色。向其他节点发送请求投票信息,如果获得大多数选票,则晋升为Leader。
Leader选举机制
-
所有的节点一开始处于选举时间(随机超时时间),处于Follower状态
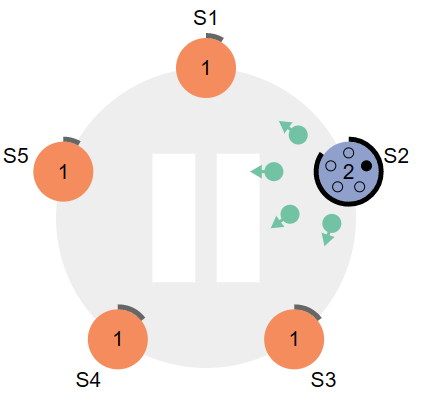
-
当其中一个节点先到完成选择时间时,将由Follower转为Candidate,并向其他节点请求投票,投票自己成为Leader,当收到的投票数超过了半数(Candidate/2+1),则可以转换为Leader,任期(Term)数为2
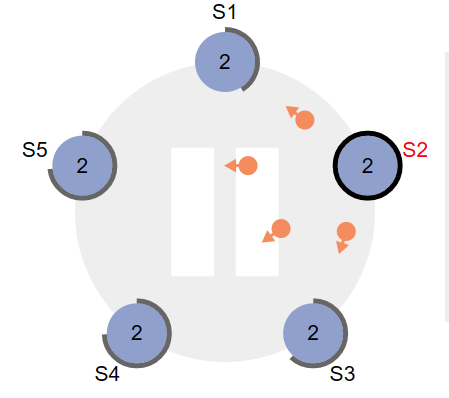
-
成为Leader之后,会持续周期性向其他节点发送heartbeat
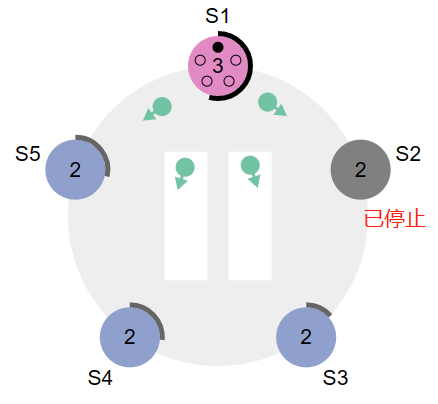
-
当Follower收到heartbeat后,会重置选举时间,如果在执行完选举时间时,还未收到heartbeat,则Follower就会转为Candidate,重新进入选举Leader,并增加任期(Term)数
-
原来的Leader恢复状态之后,收到了新Leader的heartbeat,通过任期数(Term)判断已经产生了新的Leader,就会将自己的状态由Leader转为Follower
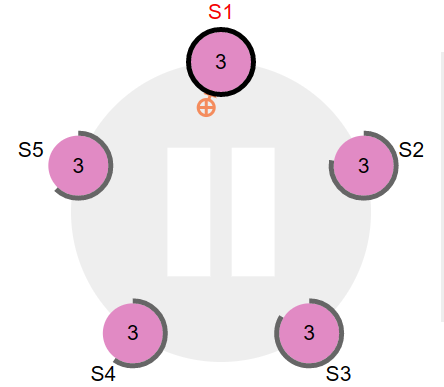
日志同步
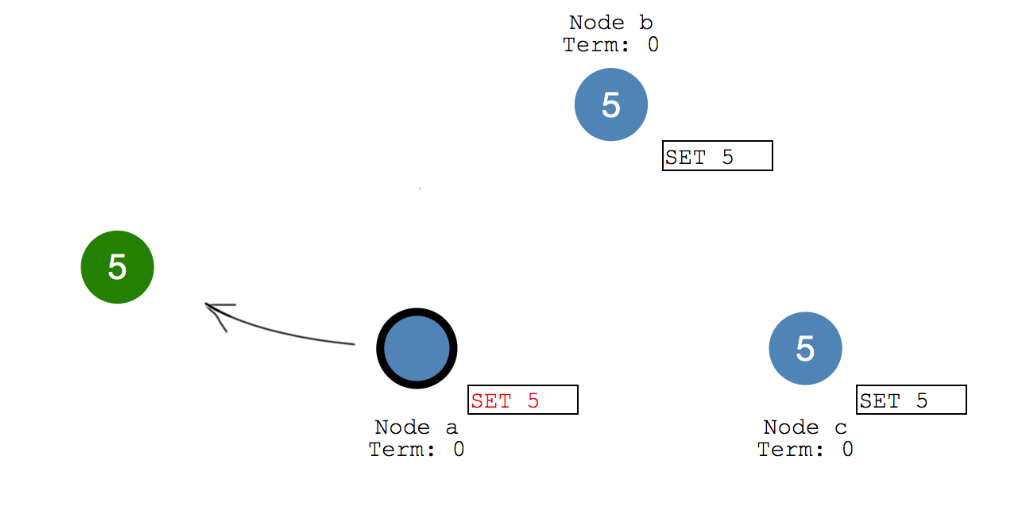
Raft算法实现日志同步的具体过程如下:
- Leader处理客户端的请求,将数据封装,并追加到自己的日志中
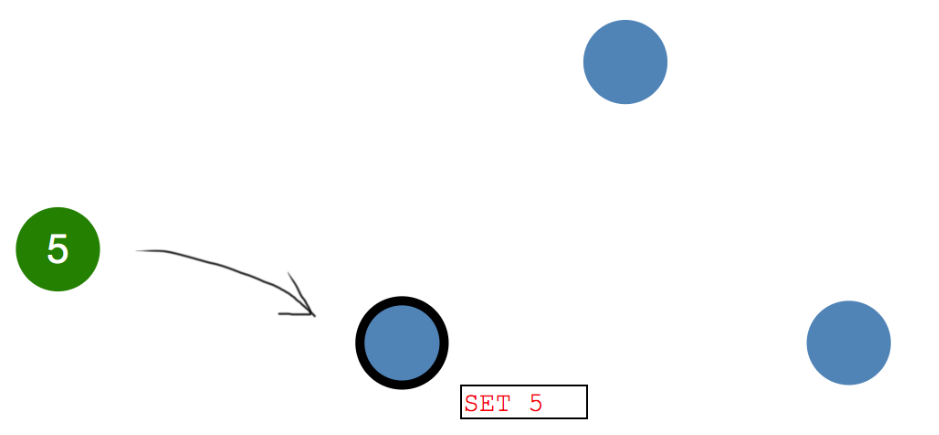
- Leader并行地向系统中所有节点发送日志复制消息
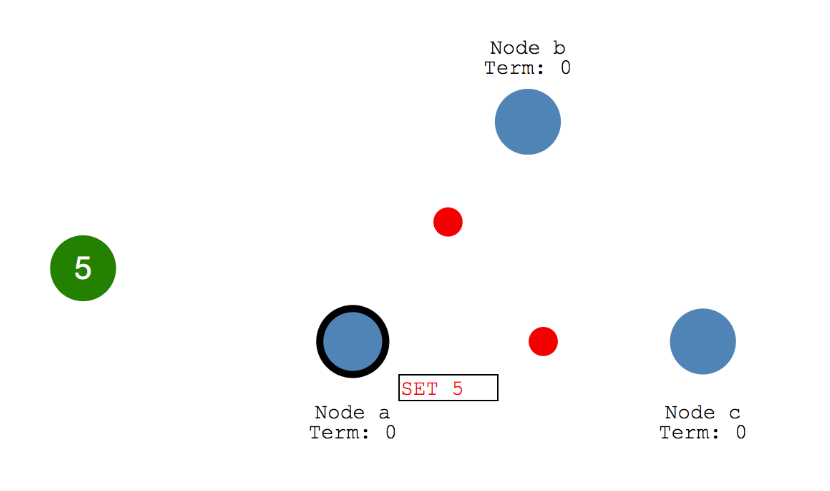
- 接收到消息的节点确认消息没有问题,则将数据追加到自己的日志中,并向Leader返回ACK表示接收成功
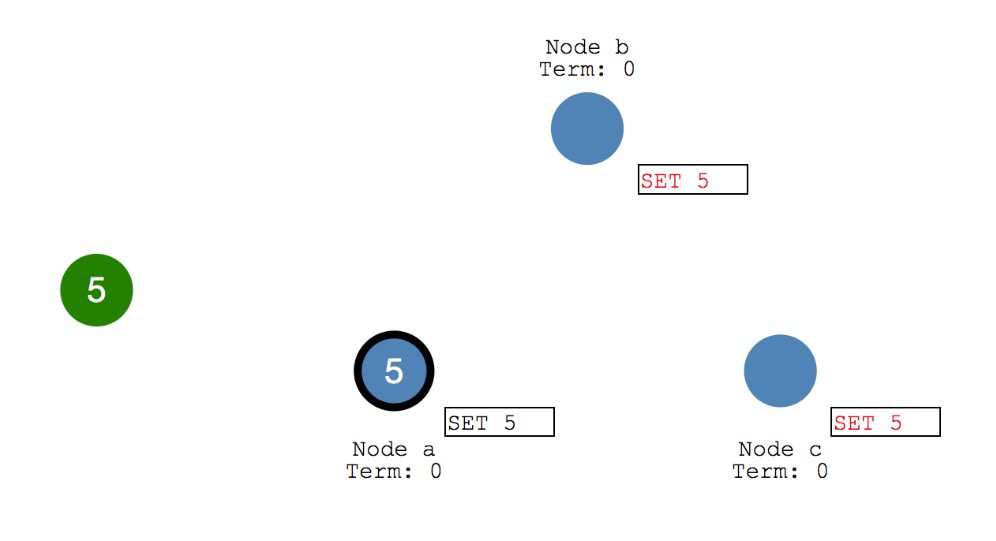
- Leader若在随机超时时间内收到大多数节点的ACK,,将该数据应用到状态机并向客户端返回成功
总结
- 选举Leader时,采用了随机超时时间控制,先超时的先进入Candidate竞选Leader,但是如果出现了相同时间进入Candidate,且获取的选票一致时,则会重新进入竞选状态。
- 选举倒计时timeout通常是 150ms ~ 300ms 直接的某个随机值
- 在集群中如果出现了脑裂问题时,产生了多个网络分区,出现多个Leader,使得分区始终有一个Leader所在的分区节点数占大部分,其余Leader所在节点处于小部分,从而导致处于小部分节点分区的Leader得不到大部分节点的ACK响应,数据无法正常Commit。直到网络正常时,多个Leader出现的时候,对比他们的term即任期(上面的步长),新的为Leader,之前小部分Leader未提交的数据则都会被舍弃,关于为什么要舍弃这些数据,需要使用CAP理论解释。
- 数据的流向只能从 Leader 节点向 Follower 节点转移
- 数据在大多数节点提交后才commit,并向客户端响应成功
参考链接